Understanding Unequal-Cost Load-Balancing
The problem of unequal-cost load-balancing
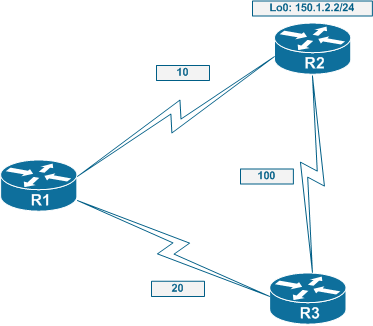
Have you ever wondered why among all IGPs only EIGRP supports unequal-cost load balancing (UCLB)? Is there any special reason why only EIGRP supports this feature? Apparently, there is. Let’s start with the basic idea of equal-cost load-balancing (ECLB). This one is simple: if there are multiple paths to the same destination with equal costs, it is reasonable to use them all and share traffic equally among the paths. Alternate paths are guaranteed to be loop-free, as they are “symmetric” with respect to cost to the primary path. If we there are multiple paths of unequal cost, the same idea could not be applied easily. For example, consider the figure below:

Suppose there is a destination behind R2 that R1 routes to. There are two paths to reach R2 from R1: one is directly to R2, and another via R3. The cost of the primary path is 10 and the cost of the secondary path is 120. Intuitively, it would make sense to start sending traffic across both paths, in proportion 12:1 to make the most use of the network. However, if R3 implements the same idea of unequal cost load balancing, we’ve got a problem. The primary path to reach R2 heading from R3 is via R1. Thus, some of the packets that R1 sends to R2 via R3 will be routed back to R1. This is the core problem of UCLB: some secondary paths may result in routing loops, as a node on the path may prefer to route back to the origin.
EIGRP’s solution to the problem
As you remember, EIGRP only uses an alternate path if it satisfies the feasibility condition: AD < FD, where AD is “advertised distance” (the peer’s metric to reach the destination) and FD is feasible distance (local best metric to the destination). The condition ensures that the path chosen by the peer will never lead into a loop, as our primary path is not subset of it (otherwise, AD would be higher or equal than FD). In our case, if we look at R1, FD=10 to reach R2 and R3’s AD=100, thus the alternate path may happen to lead into a loop. It has been proven by Garcia Luna Aceves that the feasibility condition is enough to always select loop-free alternative paths. Interested reader may look at the original paper at DUAL for the proof. In addition, if you are still thinking that EIGRP is history, I recommend you reading RFC5286 to find the same loop-free condition for Basic IP Fast Rerouting procedure (there are alternate approaches to IP FRR though). Since the feasibility condition used by EIGRP allows for selecting only loop-free alternatives it is safe to enable UCLB on EIGRP routers - provided that EIGRP is the only routing protocol - all alternate paths will never result in a routing loop.
Configuring EIGRP for Unequal-Cost Load Balancing
A few words about configuring UCLB in EIGRP. You achieve this by setting the “variance” value to something greater than 1. EIGRP routing process will install all paths with metric < best_metric*variance into the local routing table. Here metric is the full metric of the alternate path and best_metric is the metric of the primary path. By default, the variance value is 1, meaning that only equal-cost paths are used. Let’s configure a quick test-bed scenario We will use EIGRP as the routing protocol running on all routers, and set metric weights so that K1=0; K2=0; K3=1; K4=K5=0; This means that only the link delay is used for EIGRP metric calculations. Such configuration makes EIGRP metric purely additive and easy to work with.

The metric to reach R2’s Loopback0 from R1 via the directly connected link is: FD = 256*(10+10)=5120. R3 is a feasible success for the same destination, as AD = 5*256 = 1280 < FD. Thus, R1 may use it for unequal-cost load-balancing. We should set variance to satisfy the requirement (50+10+5)*256 < 256*(10+10)*variance. Here (50+5)*256 is the alternate path’s full metric. From this equation, variance > 65/20=3.25 and thus we need to set the value to at least 4 in order to utilize the alternate path. If we look at R1’s routing table we would see the following:
Rack1R1#show ip route 150.1.2.2
Routing entry for 150.1.2.0/24
Known via "eigrp 100", distance 90, metric 5120, type internal
Redistributing via eigrp 100
Last update from 155.1.13.3 on Serial0/0.13, 00:00:04 ago
Routing Descriptor Blocks:
155.1.13.3, from 155.1.13.3, 00:00:04 ago, via Serial0/0.13
Route metric is 16640, traffic share count is 37
Total delay is 650 microseconds, minimum bandwidth is 128 Kbit
Reliability 255/255, minimum MTU 1500 bytes
Loading 1/255, Hops 2
* 155.1.12.2, from 155.1.12.2, 00:00:04 ago, via Serial0/0.12
Route metric is 5120, traffic share count is 120
Total delay is 200 microseconds, minimum bandwidth is 1544 Kbit
Reliability 255/255, minimum MTU 1500 bytes
Loading 1/255, Hops 1
Notice the traffic share counters – essentially the represent the ratios of traffic shared between the two paths. You may notice that 120:37 is almost the same as 16640:5120 – that is, the amount of traffic send across a particular path is inversely proportional to the path’s metric. This represents the default EIGRP behavior set by the EIGRP process command traffic-share balanced. You may change this behavior using the command traffic-share min across-interfaces, which will instruct EIGRP to use only the minimum cost path (or paths, if any). Other feasible paths will be kept in routing table but not use until the primary path fails. The benefit is slightly faster convergence, as there is no need to insert the alternate path into RIB, as compared to scenarios where UCLB is disabled. This is how the routing table entry looks like when you enable the minimal-metric path routing:
Rack1R1#sh ip route 150.1.2.2
Routing entry for 150.1.2.0/24
Known via "eigrp 100", distance 90, metric 130560, type internal
Redistributing via eigrp 100
Last update from 155.1.13.3 on Serial0/0.13, 00:00:14 ago
Routing Descriptor Blocks:
155.1.13.3, from 155.1.13.3, 00:00:14 ago, via Serial0/0.13
Route metric is 142080, traffic share count is 0
Total delay is 5550 microseconds, minimum bandwidth is 128 Kbit
Reliability 255/255, minimum MTU 1500 bytes
Loading 1/255, Hops 2
* 155.1.12.2, from 155.1.12.2, 00:00:14 ago, via Serial0/0.12
Route metric is 130560, traffic share count is 1
Total delay is 5100 microseconds, minimum bandwidth is 1544 Kbit
Reliability 255/255, minimum MTU 1500 bytes
Loading 1/255, Hops 1
How CEF implements Unequal-Cost Load-Balancing
And now, a few words about data plane implementation of UCLB. It’s not documented on Cisco’s documentation site, and I first read about it the Cisco Press book “Traffic Engineering with MPLS” by Eric Osborne and Ajay Simha. The method does not seem to change since then.
As you know, the most prevalent switching method for Cisco IOS is CEF (we don’t consider distributed platforms). Layer 3 load-balancing is similar to load-balancing used with Ethernet Port-Channels. Router takes the ingress packet, hashes source and destination IP addresses (and maybe L4 ports) and normalizes the result to be, say, in range [1-16] (the result is often called “hash bucket”). The router than uses the hash bucket as the selector for one of the alternate paths. If the hash function distributes IP src/dst combinations evenly among the result space, then all paths will be utilized equally. In order to implement unequal balancing, an additional level of indirection is needed. Suppose you have 3 alternate paths, and you want to balance them in proportion 1:2:3. You need to fill the 16 hash buckets with the path selectors to maintain the same proportion 1:2:3. Solving the simply equation: 1*x+2*x+3*x=16 we find that x=2.6 or 3 rounded. Thus, to maintain the proportions 1:2:3 we need to associate 3 hash buckets with the first path, 6 hash buckets with the second part and the remaining 7 hash buckets with the third path. This not exactly the wanted proportion, but it is close. Here is how the “hash bucket” to “path ID” mapping may look like to implement the above proportion of 1:2:3.
Hash | Path ID
--------------
[01] -> path 1
[02] -> path 2
[03] -> path 3
[04] -> path 1
[05] -> path 2
[06] -> path 3
[07] -> path 1
[08] -> path 2
[09] -> path 3
[10] -> path 2
[11] -> path 3
[12] -> path 2
[13] -> path 3
[14] -> path 2
[15] -> path 3
[16] -> path 3
Once again, provided that the hash function distributes inputs evenly among all buckets, the paths will be used in the desired proportions. As you can see, the way that control plane divides traffic flows among different paths may be severely affected by the data plane implementation.
CEF may load-balance using per-packet or per-flow granularity. In the first case, every next packet of the same flow (src/dst IP and maybe src/dst port) is routed across the different paths. Why this may look like a good idea to better utilize all paths, it usually results in packets arriving out of order. The result is poor application performance, since many L4 protocols are better suited to packets arriving in order. Thus, in real-world, the preferred and the default load-balancing mode is per-flow (often called per-destination in CEF terminology). To change the CEF load-balancing mode on the interface, use the interface level command ip load-sharing per-packet|per-destination. Notice that it only affects the packets ingress on the configured interface.
Let’s look at the CEF data structures that may reveal information on load-balancing implementation. When you issue the following command, you may reveal all alternative adjacencies used to route the packet toward the prefix in question. This is the first part of the output.
Rack1R1#show ip cef 150.1.2.2 internal
150.1.2.0/24, version 77, epoch 0, per-destination sharing
0 packets, 0 bytes
via 155.1.13.3, Serial0/0.13, 0 dependencies
traffic share 37
next hop 155.1.13.3, Serial0/0.13
valid adjacency
via 155.1.12.2, Serial0/0.12, 0 dependencies
traffic share 120
next hop 155.1.12.2, Serial0/0.12
valid adjacency
The next block of information is more interesting. It reveals those 16 hash buckets, loaded with the path indexes (after the “Load distribution” string). Here zero means the first path, and 1 means the second alternate path. As we can see, 4 buckets are loaded with the path “zero”, and 12 buckets are loaded with the path “one”. The resulting share 4:12=1:3 is very close to 37:120, so in this case the data plane implementation did not change the load-balancing logic too much. The rest of the output details every hash bucket index and associated output interface, as well as the number of packets switches using the particular hash bucket. Keep in mind, that only CEF switched packets are reflected in the statistics, so if you use the ping command off the router itself, you will not see any counters incrementing.
[...Output Continues...]
0 packets, 0 bytes switched through the prefix
tmstats: external 0 packets, 0 bytes
internal 0 packets, 0 bytes
Load distribution: 0 1 0 1 0 1 0 1 1 1 1 1 1 1 1 1 (refcount 1)Hash OK Interface Address Packets
1 Y Serial0/0.13 point2point 0
2 Y Serial0/0.12 point2point 0
3 Y Serial0/0.13 point2point 0
4 Y Serial0/0.12 point2point 0
5 Y Serial0/0.13 point2point 0
6 Y Serial0/0.12 point2point 0
7 Y Serial0/0.13 point2point 0
8 Y Serial0/0.12 point2point 0
9 Y Serial0/0.12 point2point 0
10 Y Serial0/0.12 point2point 0
11 Y Serial0/0.12 point2point 0
12 Y Serial0/0.12 point2point 0
13 Y Serial0/0.12 point2point 0
14 Y Serial0/0.12 point2point 0
15 Y Serial0/0.12 point2point 0
16 Y Serial0/0.12 point2point 0
refcount 6
Any other protocols supporting Unequal Cost Load-Balancing?
As we already know, nor OSPF, ISIS or RIP can support UCLB, as they cannot test that the alternate paths are loop free. In fact, all IGP protocols could be extended to use this feature, as specified in the above-mentioned RFC5286. However, this is not (yet?) implemented by any well-known vendor. Still, one protocol supports UCLB in addition to EIGRP. As you may have guessed this is BGP. What makes BGP so special? Nothing else but the routing-loop detection feature implemented for eBGP session. When a BGP speakers receives a route from the external AS, it looks for its own AS# in the AS_PATH attribute, and discards matching routes. This prevents routing loops on AS-scale. Additionally, this allows BGP to use alternative eBGP paths for unequal-cost load balancing. The proportions for the alternative paths are chosen based on the special BGP extended community attribute called DMZ Link bandwidth. By default, this attribute value is copied from the bandwidth of the interface connecting to the eBGP peer. To configure UCLB with BGP you need the configuration similar to the following:
router bgp 100
bgp maximum-path 3
bgp dmzlink-bw
neighbor 1.1.1.1 remote-as 200
neighbor 1.1.1.1 dmzlink-bw
neighbor 2.2.2.2 remote-as 200
neighbor 2.2.2.2 dmzlink-bw
In order for paths to be eligible for UCLB, they must have the same weight, local-preference, AS_PATH length, Origin and MED. Then, the local speaker may utilize the paths inversely proportional to the value of DMZ Link bandwidth attribute. Keep in mind that BGP multipathing is disabled by default, until you enable it with the command bgp maximum path. IBGP speakers may use DMZ Link bandwidth feature as well, for the paths injected into the local AS via eBGP. In order for this to work, DMZ Link Bandwidth attribute must be propagated across the local AS (send-community extended command) and the exit points for every path must have equal IGP costs in the iBGP speaker’s RIB. The data-plane implementation remains the same as for EIGRP multipathing, as CEF is the same underlying switching method.
So how should I do that in production?
Surprisingly enough, the best way to implement UCLB in real life is by using MPLS Traffic Engineering. This solution allows for high level of administrative control, and is IGP agnostic (well they say you need OSPF or ISIS, but you may use verbatim MPLS TE tunnels even with RIP or EIGRP). It is safe to use unequal-cost load-balancing with MPLS TE tunnels because they connect two nodes using “virtual circuits” and no transit node ever performs routing lookup. Thus, you may create as many tunnels between the source and the destination as you want, and assign the tunnel bandwidth values properly. After this, CEF switching will take care of the rest for you.
Further Reading
Load Balancing with CEF
Unequal Cost Load Sharing
CEF Load Sharing Details
