Tuning OSPF Performance
In this blog post we are going to discuss some OSPF features related to convergence and scalability. Specifically, we are going to discuss Incremental SPF (iSPF), LSA group pacing, and LSA generation/SPF throttling. Before we begin, let's define convergence as the process of restoring the stable view of network after a change, and scalability as the property of the routing protocol to remain stable and well-behaving as the network grows. In general, these two properties are reciprocal, i.e. faster convergence generally means less stable and scalable network and vice versa. The reason for that is that faster convergence means that the routing protocol is “more sensitive” to oscillating or “noisy” processes, which in turn makes it less stable.
Incremental SPF
The classic Dijkstra SPF algorithm complexity (or roughly saying, the process run-time) depends on the particular network topology, but it is said to be proportional to N*log(N) in a non-densely connected topology, where N is the number of nodes in the area, see [RFC1245]. The computation complexity used to be a limiting factor for old, slow routers of the 90’s, where a single SPF run could hog the CPU dramatically. Modern routers take an order of tens, max hundreds of milliseconds for single full SPF runs even for the largest topologies. The runtime could be further reduced using the SPF algorithm optimization know as incremental SPF, which has been developed quite some time ago see [ARPOPT] (notice the year 1980 on the paper and the name of the main author - it’s no other than Eric Rosen!).
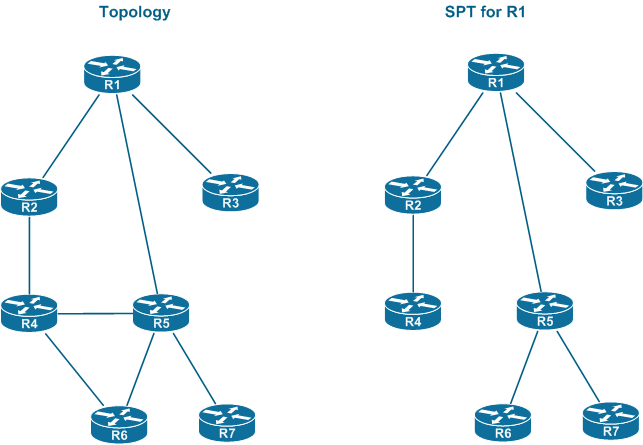
The implementation might look a bit sophisticated, but the main idea of iSPF is keeping the SPT structure after the first SPF calculation and using it for further computation optimizations. As you remember, the goal of SPF is building an SPT (shortest-path tree) on the network topology graph, rooted at the node that runs the computations. Look at the sample topology (taken from [JDOYLE]) and the SPT for router R1 below:

If R1 would retain the SPT after SPF calculations (at the expense of extra memory) the following three properties could be used for SPF calculation optimization:
Property 1 If a node added or removed to or from the topology appears to be a leaf node to the saved SPT, there needs to be a very simple computation performed to add new routes. Essentially, the existing tree is simply “extended” by one node and distance-vector like computations can be performed:

The same optimization property might be utilized when a stub link is added or removed to or from any node in the network.
Property 2 There is a link failure, and the link is NOT part of the saved SPT. For example, consider the link between R4 and R5 fails. This link is not part of the saved SPT, and therefore, there is no need to perform any SPF calculation at all!

Even though there is great benefit in not making any SPF calculations, it’s hard to predict how many link failures would cause such effect. Besides, different routers would have different SPTs and a link failure that does not affect one SPT, might affect the others.
Notice that in the case of transit link addition or link cost change, i.e. in the case when graph “connectivity” increases, this property would not work and the new tree should be built.
Property 3: The last property is more generic. Assume there is a transit link failure in the topology and it affects a part of the saved SPT, which means properties (1) and (2) do not apply. For example, imagine there is a link fault between R2 and R4. Still, we only need to re-calculate the paths for the nodes downstream of the failure, based on our existing SPT. So the router would initiate SPT calculations from R1 to R4 only, not ever bothering with other nodes. However, if there is a link failure between R1 and R5, then the router would have to recalculate the paths to R5, R6 and R7 – the nodes on the downstream tree under the failed link.

One effect is that the father away from the root node the failure is, the less computations potentially have to be done. Even though remote link failures take more time to propagate to the local node via LSA flooding, they result in shorter iSPF run-time, as the amount of downstream affected nodes is smaller. Once again, since different routers have different SPTs for the topology, the same failure may have different effects on iSPF efficiency for different routers.
Another important fact is that this feature performs better in sparsely connected networks. In the asymptotic case of a fully-meshed topology, a single transit-link failure would cause re-running the SPF for all nodes, resulting in the same performance as classic SPF.
iSPF and PRC
Among all the iSPF properties, property (1) is probably the most important and effective in practice. This property puts OSPF on par with the Partial Route Computation (PRC) feature found in IS-IS. The PRC feature made ISIS very effective in situations when new stub links were added, as ISIS propagates network reachability information separately from topological information, thanks to LSP’s TLV-based structure. Different TLVs are used for IS-node reachability information and network prefixes associated with the node. When an ISIS router receives an LSP that only lists network prefix change, it performs partial SPF recalculation, based on distance-vector logic, by adding the new prefix in the routing table with the cost of reaching the originating router, similar to property (1). Only a change in the transit link status would trigger full SPF computation in ISIS.
In the past, the PRC feature made ISIS more scalable for a single area design when compared to OSPF. The problem with OSPF was that topological information and network reachability information for router links were conveyed in a single type-1 LSA. Whether there was a transit link failure or simply a stub link going up or down, OSPFv2 had to perform complete SPF calculation as this was reflected using the same event that would report a network prefix or metric. Only type-3 and type-5 LSAs would have triggered PRC in OSPFv2. There was a trick to make better use of PRC with OSPFv2 – advertise all connected interfaces via redistribution, which resulted in type-5 LSAs being flooded. However, the tradeoff was that type-5 LSA’s flooding scope was the whole routing domain, plus type-5 LSAs have the largest size among other LSA types, not to mention slightly added configuration complexity.
The introduction of iSPF made OSPF as effective as ISIS as far as SPF computation goes. To be fair though, we should mention that iSPF was also added to ISIS, so now both protocols are equally effective for SPF computations. By default, iSPF is disabled and could be enabled using the command ispf under the routing process configuration mode. By enabling iSPF you will make OSPF use slightly more memory than by default, propotional to the 2*N where N is the number of nodes in the area. This due to the fact that a spanning tree for N nodes has exactly N-1 edges.
LSA Group Pacing
As you remember, OSPF LSAs have two important attributes – age and checksum. The age field is needed to guarantee wiping of the outdated information and the checksum is needed to maintain the information integrity. By default, the maximum LSA age is one hour, and the originating router is supposed to re-flood the LSAs every 30 minutes. In addition to that, the router needs to run periodic check-summing on all LSAs.
The way Cisco routers originally did that was by running a refresh procedure every 30 minutes and refreshing every self-originated LSA in the database, no matter how old it was. This would result in sudden CPU spikes every 30 minutes in case of large databases in addition to bursty LSA flooding. Every router in the routing domain in turn would have to receive and process a large amount of LSA information. This is a good example of a “synchronization” problem. In addition to this refreshing, every 10 minutes a router would run periodic check-summing and an aging procedure, and flush any aged non-self-originated or corrupted LSAs.
In order to alleviate the 30-minute refreshing problem, Cisco IOS implemented an independent aging procedure for every LSA in the LSDB. A short period scheduler would scan the database and decrement every LSA’s age individually. Only LSAs that were close to their “half-life” of 30 minutes would be re-flooded. This is the opposite of doing a “complete” refresh every 30 minutes. However, this process would result in many quick floods during the 30-minutes interval, as a result of independent aging. This might be viewed as a “fragmentation” problem.
The “balanced” solution is known as “group pacing”. Instead of refreshing an LSA instantly as soon as it reaches its half-life age, the router would wait a “pacing interval” amount of time to group various LSAs with similar age. The pacing interval is normally shorter than the 30 minute “grand interval” and defaults to 240 seconds. Thus, a router would attempt to group LSAs with similar lifetime and refresh them simultaneously.

Look at the diagram above for the illustration of the concept. Original refreshing procedure would produce large bursts of LSA flooding every 30 minutes. The individual aging would result in fragmentary re-flooding. The group pacing feature would introduce controlled bursting – the shorter the interval, the smaller are the “bursts”.
The same pacing concept could be applied to check-summing and aging. Specifically, if we run individual timers for ever LSA, and aim at check-summing and aging every 10 minutes, we would get the same fragmentary “CPU-spiking” patterns. Instead of running the process individually for every LSA, grouping based on the same group pacing interval could be used for the purpose of check-summing and aging, so a small batch of LSAs that are close to being aged out or check-summed are processed together.
The IOS commands to control the various group pacing intervals are:
timers pacing ?
flood OSPF flood pacing timer
lsa-group OSPF LSA group pacing timer
retransmission OSPF retransmission pacing timer
The LSA group interval is used for the refreshing/aging/checksumming grouping discussion above. The “retransmission” keyword is a bit more interesting. Every time the router needs to retransmit an un-acknowledged LSA over an adjacency, it might wait some time to group it with other un-acknowledged LSAs. This is the same grouping principle, which allows for better packing of LSA information in IP packets. Of course, the “retransmission” grouping interval is much shorten than LSA grouping and measured in milliseconds.
The “flood” keyword serves a similar purpose, but controls the interface LSA flood list. For every interface the OSPF process keeps the “flood list”, which contains the LSAs that have been generated or received and are destined to be flooded out of this interface. Instead of flooding every LSA as soon as it hits the list, the OSPF process would wait the “pacing interval” for more potential LSAs and pack them in a single update packet. This process optimizes bandwidth and CPU usage on both sides of the adjacency. Of course, the resolution for this timer is set in milliseconds, due to the real-time nature of the process.
So what are the optimal group pacing timer values? Probably the defaults, which could be found as follows:
Rack1R5#show ip ospf | inc transmission|pacing
LSA group pacing timer 240 secs
Interface flood pacing timer 33 msecs
Retransmission pacing timer 66 msecs
For very large LSDBs, you generally want to set the LSA group pacing timer to be inversely proportional to the size of database. This ensures less “surges” when flooding large LSA batches. Keep in mind that tuning LSA group pacing improves OSPF performance and thus protocol scalability, but does not affect convergence speed.
SPF and LSA Generation Throttling
Throttling is the general process of slowing down responses to the frequently oscillating events such as link flaps. The general idea is to reduce resource wastage in unstable situations and wait till the situations calm down. If you have a link that flaps up and down frequently, you may want to suppress the links state information flooding until it becomes stable (either stable down or up). Throttling is critical for ensuring network stability and thus protocol scalability. This procedure is also very similar to event dampening, though they differ a little bit – dampening would suppress events while throttling simply increases the response times, hoping that oscillations would stop or at least the responses do not follow the same oscillating pattern but filter the high-frequency noisy events.
The general idea is as follows. When an event occurs, e.g. a link goes down or new LSA arrives, do not respond to it immediately, e.g. by generating an LSA or running SPF, but wait some time, hoping to accumulate more similar events, e.g. waiting for the link to go back up, or more LSAs arriving. This could potentially save a lot of resources, by reducing the number of SPF runs or amount of LSAs flooded. The question is – how long should we hold or throttle the responses? Ideally, it would be nice to adapt this interval according to the network conditions – i.e. make it longer when the network is unstable and shorter under stable conditions. Cisco implements an exponential back-off timer to implement this idea. Here is how it works.
The exponential back-off is defined using three parameters – start interval, increment, and max_wait time specified using the command timers throttle spf start increment max_wait.Suppose the network was stable for a relatively long time, and then an event such as LSA arrival has occurred. The router delays SPF computations for the start amount if milliseconds and sets the next hold-time to increment milliseconds. Next, if an event occurs after the start wait window expired, the event would be held for processing until the increment milliseconds window expire, but the next hold-time would be doubled, i.e. set to 2*increment. Effectly, every time an event occurs during the current hold-time window, the processing is delayed until the current hold-time expires and the next hold-time interval is doubled. The hold-time grows exponentially until it reaches the max_wait value. After this, every event received during current hold-time window would result in the next interval being equal to the constant max_wait. This ensures that exponential growth is limited by a ceiling value. If there are no events for the duration of 2*max_wait milliseconds, the hold-time window is reset back to the start value, assuming the network returned to stable condition.
Look at the figure below.

The first event schedules SPF run in start milliseconds. At the same time, the next interval is set to increment milliseconds. Since there is an event during the second hold interval, the third hold interval is set to 2xincrement. There is another event during the third window, and this sets the forth window to 4xincrement. However, in our case this exceeds the max_wait value, and thus the forth hold-time interval equals max_wait milliseconds. There are more events during the forth interval, but since the maximum hold-time value has been reached, the fifth interval is set to max_wait milliseconds. Since there are no events during the firth and sixth intervals, the hold-time is reset to start milliseconds again.
Although SPF response to LSA arrivals has been used in the above examples, the same idea applies to new LSA generation as response to local link events. This could be controlled using the LSA generation throttling command timers throttle lsa start increment max_wait. Both SPF and LSA generation throttling are on by default and you may probably want to reduce their values only if you really need to speed up your network convergence. However, keep in mind that improving response time automatically results in less stable routing protocol behavior.
Summary and Further Reading
We briefly discussed three extensions to OSPFv2 protocol: iSPF, LSA group pacing and event throttling. The first two features improve OSPF performance, while the last one allows for better scalability and dynamic adaptation to unstable network topologies. Even though these and other OSPFv2 enhancements significantly increase its scalability, the more general design features such as area partitioning, network summarization and event dampening should not be neglected. Lastly, if you haven’t done so yet, I would strongly suggest you to read the following publications:
[RFC1245] “OSPF Protocol Analysis”, J. Moy
[JDOYLE] “OSPF and IS-IS: Choosing an IGP for Large-Scale Networks”, J. Doyle
[LSAP] ”OSPF LSA Group Pacing”
[THROT] "OSPF Shortest Path First Throttling"
[ARPOPT] “ARPANET Routing Algorithm Improvements” E. Rose et al
