What is Overlay Transport Virtualization?
Introduction
Recently, there were discussions going around about Cisco’s new datacenter technology – Overlay Transport Virtualization (OTV), implemented in Nexus 7k data-center switches (limited demo deployments only). The purpose of this technology is connecting separated data-center islands over a convenient packet switched network. It is said that OTV is a better solution compared to well-known VPLS, or any other Layer 2 VPN technology. In this post we are going to give a brief comparison of two technologies and see what benefits OTV may actually bring to data-centers.
VPLS Overview
We are going to give a rather condensed overview of VPLS functionality here, just to have a baseline to compare OTV with. A reader is assumed to have solid understanding or MPLS and Layer 2 VPNs, as technology fundamentals are not described here.

- VPLS provides multipoint LAN services by extending a LAN cloud over a packet switched network. MPLS is used as a primary transport for tunneling Ethernet frames, however it could be replaced with any suitable tunneling solution, such as GRE or L2TPv3 that runs over a convenient packet switched network. That is, to say at least, VPLS could be transport agnostic, if required. The main benefit of label-switched paths is the ability to leverage MPLS-TE, which is very important to service-providers.
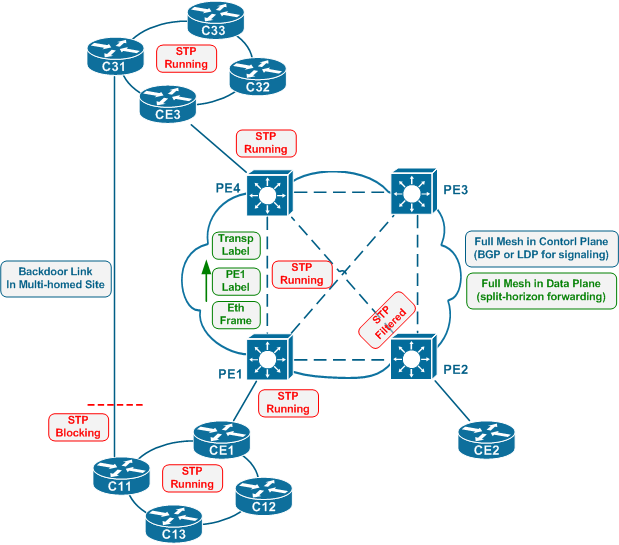
- The core of VPLS functionality is the process of establishing a full-mesh of pseudowires between all participating PE's. If a VPLS deployment has N PE's, every PE needs to allocate and advertise N-1 different labels to N-1 remote PEs that they should use when encapsulating L2 packets sent to the advertising PE. This is required in order for the advertising PE to be able to distinguish frames coming from different remote PEs and properly perform MAC-address learning.
- There are two main different methods for MPLS tunnel signaling. Those are full mesh of LDP sessions and full-mesh of BGP peerings. Notice that LDP-based standard does not specify any auto-discovery technique and those could be selected at vendor’s discretion (e.g. RADIUS). BGP-based signaling technique allows for auto-discovery and automatic label allocation using BGP multiprotocol extensions.
- VPLS utilizes the same data-plane based learning that "classic" Ethernet uses. When a frame is received over a pseudowire, its source MAC address is associated with the “virtual port” and corresponding MPLS label. When a multicast frame or a frame with unknown unicast destination address is received it is flooded out of all ports including the pseudowires (virtual ports).
- The full mesh of pseudowires allows for simplified forwarding in VPLS core network. Instead of running STP to block redundant connection, split horizon data-plane forwarding rule is used. A frame received on a pseudowire is forwarded only out of physical ports, and not out of any other pseudowires.
- VPLS does not facilitate control-plane adderess learning, but may facilitate some special signaling to explicitly withdraw MAC addresses from remote PEs when a topology change is detected on the local site. This is especially important in multi-homed scenarios, when MAC address mobility could be a reality.
VPLS Limitations
The following is the list of VPLS limitations, which are inherently rooted in the Ethernet technology:
- Data-plane learning and flooding are still in use. This fundamental property makes Ethernet plug-and-play technology, but results in poor scalability. Essentially, a single LAN segment is one fault domain, as any change in the topology requires re-flooding of frames and generates sudden bursts of traffic. A topology change in single site may propagate to other sites across the VPLS core (by use of signaling extensions) and cause MAC address re-learning and flooding.
- Ethernet addressing is inherently flat and non-hierarchical. MAC addresses serve the purpose of identifying endpoints, not pointing their locations. This makes troubleshooting large Ethernet topologies very challenging. In addition to this, MAC addresses are non-summarizable which, coupled with learning & flooding behavior, results in uncontrolled address-table growth for all devices in Ethernet domain.
- Spanning Tree is still used in CE domains, which results in slower convergence and suboptimal bandwidth usage. Since STP blocks all redundant links the links' bandwidth is effectively wasted. Plus, the links close the root bridge are more congested than the the STP leaves. The use of MSTP or PVST could alleviate this problem, but traffic engineering becomes complicated due to multiple logical topologies.
- If a customer site is multihomed in VPLS core network, STP needs to be running across the core to ensure blocking of redundant paths, as VPLS does not detect this. This further worsens convergence times and affects stability. There is an alternative, not yet standartized approach for selecting a designated forwarder for multi-homed sites, which does not rely on STP.
- VPLS does not have native multicast replication support. Multicast frames are flooded out of all pseudowires, even though IGMP snooping may reduce the amount of flooding on local physical ports. Ineffective PE-based multicast replication limits the use of heavyweight multicast applications in VPLS.
Of course, the community came with some solutions to the above problems. Firstly, the problem of address-table growth could be alleviated using MAC-in-MAC (IEEE 802.1ah) encapsulation for customer frames. In this solution, PE devices only have to learn other PE’s MAC addresses, or the MAC-in-MAC stacking devices could be pushed down to the customer network. Even simpler, CE devices could be replaced with routers, thus exposing only a single CE MAC address to the VPLS cloud. Next, there is a lot of work being done for multicast optimization in VPLS. The root cause lies in adapting the main underlying transports – MPLS label switching – to effectively handling multicast traffic. The solution uses point-to-multipoint LSPs and either M-LDP or RSVP-TE extensions to signal those. It is not yet completely standardized and widely adopted, but the work is definitely in progress. However, the main scaling factor of Ethernet – topology agnostic control plane with uncontrolled data-plane learning is not addresses in VPLS extensions so far.
As an alternative to using sophisticated M-LSPs, the multicast problem could be “resolved” by co-locating additional Layer 3 VPN topology and running Layer 3 mVPNs. A “proxy” PIM router deployed at every site will process the IGMP messages and signal multicast trees in the core network. While this solution is not as elegant as using P2MP LSPs and introduces additional operational expenses, but it nonetheless offers a working alternative.
Overlay Transport Virtualization
Regardless the loud name, from technical standpoint OTV looks like nothing more than VPLS stripped off MPLS transport and having optimized multicast handling similar to one used in Draft Rosen's Layer 3 mVPNs. The are some Ethernet flooding behavior improvenments, but those are questionable. Let’s see how OTV works. Notice that this time we use the notion of CE devices, not PE, as OTV is the technology to be deployed at customer’s edge.

- CE devices connect to customer Ethernet clouds and face a provider packet-switching network (or enterprise network core) using a Layer 3 interface. Every CE device creates an overlay tunnel interface that is very much similar to MDT Tunnel interface specified in Draft Rosen. Only IP transport is required in the core and thus the technology does not depend on MPLS transport.
- Just like with Rosen’s mVPNs all CE’s need to join a P (provider) multicast group to discover other CE's over the overlay tunnel. The CE's then establish a full mesh of IS-IS adjacencies with other CE's on the overlay tunnel. This could be thought as an equivalent for full-mesh of control-plane link in VPLS. The provider multicast group is normally an ASM or Bidir group.
- IS-IS nodes (CEs) flood LSP information including the MAC addresses known via attached physical Ethernet ports to all other CE’s. This is possible due to flexible TLV structure found in ISIS LSPs. The same LSP flooding could be used to remove or unlearn a MAC address if the local CE finds it unavailable.
- Ethernet forwarding follows the normal rules, but GRE encapsulation (or any other IP tunneling) is used when sending Ethernet frames over the provided IP cloud to a remote CE. Notice that GRE packets received on overlay tunnel interfaces do NOT result in MAC-address learning for encapsulated frames. Furthermore, unknown unicast frames are NOT flooded out of overlay tunnel interface – it is assumed that all remote MAC addresses are signaled via control plane and should be known.
- Multicast Ethernet frames are encapsulated using multicast IP packets and forwarded using provider multicast services. Furthermore, it is possible to specify a set of “selective” or “data” multicast groups that are used for flooding specific multicast flows, just like in mVPNs. Upon a reception of an IGMP join, a CE will snoop on it (similar to the classic IGMP snooping) and translate into core multicast group PIM join. All CE's receiving IGMP reports for the same group will join the same core multicast tree and form an optimal multicast distribution structure in the core. The actual multicast flow frames will them get flooded down the selective multicast tree to the participating nodes only. Notice one important difference from mVPNs – the CE devices are not multicast routers, they are effectively virtual switches performing IGMP snooping and extended signaling in provider core.
- OTV handles multi-homed scenarios properly, without running STP on top the overlay tunnel. If two CE’s share the same logical backdoor link (i.e. they hear each other ISIS hello packets over the link) one of the devices is elected as appointed (aka authoritative) forwarder for the given link (e.g VLAN). Only this device actually floods and forwards the frames on the given segment, thus eliminating Layer 2 forwarding loop. This concept is very similar o electing a PIM Assert winner on a shared link. Notice that this approach is simialar to VPLS draft proposal for multihoming, but uses IGP signaling instead of BGP.
- OTV supports ARP optimization in order to reduce the amount of broadcast traffic flooded across the overlay tunnel. Every CE may snoop on local ARP replies and use the ISIS extensions to signal IP to MAC bindings to remote nodes. Every CE will then attempt to respond to an ARP request using its local cache, instead of forwarding the ARP packet over the core network. This does not eliminate ARP, just reduces the amount of broadcast flooding
Now for some conclusions. OTV claims to be better than VPLS, but this could be argued. To begin with, VPLS is positioned as provider edge technology and OTV is customer-edge technology. Next, the following list captures similarities and differences between the two technologies:
- The same logical full-mesh of signaling is used in the core. IS-IS it outlined in the patent document, but any other protocol could be obviously used here, e.g. LDP or BGP. Even the patent document mentions that. What was the reason to re-inventing the wheel? The answer could be “TRILL” as we see in the following section. But so far switching to new signaling makes little sense in terms of benefits.
- OTV runs over native IP, and does not require underlying MPLS. Like we said before, it was possible to simple change VPLS transport to any IP tunneling technique instead of coming with a new technology. By missing MPLS, OTV loses the important ability to signal optimal path selection in provider networks at the PE edge.
- Control Plane MAC-address learning is said to reduce broadcast in the core network. This is indeed accomplished but at a significant price. Here is the problem: If a topology change in one site is to be propagated to other sites, control plane must signal the removal of locally learned MAC addresses to the remote sites. Effectively, this will translate data-plane “black-holing” until the MAC addresses are not re-learned and signaled again, as OTV does not flood over the IP core.The things are even worse in control plane. A topology change will flush all MAC addresses known to a CE an result in LSP flooding to all ajdacent nodes. The amount of LSP replication could be optimized using IS-IS mesh-groups, but at least N copies of LSP should be sent, where N is the number of adjacencies. As soon as new MACs are learned, additional LSP will be flooded out to all neighbors! Properly controlling LSP generation, i.e. delaying LSP sending may help reduce flooding but again will result in convergence issues in data plane.
To summarize, the price paid for flooding reduction is slower convergence in presence of topology changes and control-plane scalability challenges. The main problem – topology unawareness that leads to the need of re-learning MAC address is not addressed in OVT (yet). However, if you think that data-plane flooding in data-centers could be very intensive, the amount of control plane flooding introduced could become acceptable.
- Optimized multicast support seems to be the only big benefit of OTV that does not result in significant trade-offs. Itroducing native multicast it’s probably due to the fact that VPLS multicasting is still not standardized, while datacenters need it now. The multicast solution is a copy of mVPNs model and not something new and exciting, like M-LSPs are. Like we said before, the same idea could be deployed in VPLS scenarios by means of co-located mVPN. Also, when deployed over SP networks, this feature requires SP multicast support for auto-discovery and optimized forwarding. This is not a major problem though, and OTV has support for unicast static discovery.
To summarize, it looks like OTV is an attempt to fast-track a slightly better “customer” VPLS in datacenters, while IETF folks struggle for actual VPLS standardization. The technology is “CE-centric”, in essence that it does not require any provider intervention with exception to providing multicast and L3 services. It is most likely that OTV and VPLS projects are being carried by different teams that are being time-pressed and thus don’t have resources to coordinate their efforts and come with a unified solution. There are no huge improvements so far in terms of Ethernet optimization, with except to reduced flooding in network core, traded for control-plane complexity. At its current form, OTV might look a bit disappointing, unless is a first step to implementing TRILL (Transport Interconnection for Lots of Links) – new IETF standard for routing bridges.
Meet TRILL
Before we being, it is worth noting that IETF TRILL project somewhat parallels IEEE 802.1aq standard development. Both standards propose replacement of STP with link-state routing protocol. We’ll be discussing mainly RBridges in this post, due to the fact that more open information is available on TRILL. Plus, IETF papers are much easier to read compared to IEEE documents!
Like mentioned above, RBridges is short name for Routing Bridges, the project pioneered by Radia Perlman of Sun Microsystems. If you remember, she is the person who invented the original (DEC) STP protocol. In the new proposal, all bridges become aware of each other and the whole topology by using IS-IS routing protocol. Every bridge has e “nickname” - a 16-bit identified, which addresses the router in the global topology (similar to OSPF router-id). Once the topology is built, the switches operate as following:

- RBridges dynamically learn MAC addresses and associate them with respective VLANs on the customer-facing ports. When a frame needs to be switched out, the RBridges looks up the destination MAC address and finds the remote bridge nickname associated with this MAC. The frame is then encapsulated using three headers. The intermediate RBridges then use the TRILL header for actual hop-by-hop routing to the egress RBridges. Notice that the outer header contains the MAC addresses of two directly connected RBridges, just like it would be in case of routing. The TRILL header has a hop-count field that is similar to IP TTL. Every bridge in the path decrements this field and drops the frame if time to live falls to zero, just like convenient routers do.
- If the destination address is not known to the ingress RBridge, the frame is flooded in controlled manner, using special destination TRILL address. The shortest-path trees constructed using the link state information are used for flooding and RPF check is performed on every RBridges to eliminate transient routing loops. It is important to point out that every transit RBridges on the path of the flooded frame does not learn the inner MAC address unless it has the inner VLAN locally configured. Thus, transit RBridges limit their address table sizes only to the addresses of other RBridges. Every egress RBridges receiving the TRILL-encapsulated frame will learn the inner source MAC address and associate it with the sending RBridge nickname. This will allow the egress RBridges to properly route the response frames.
- Any link failure will result in SPF topology re-computations but will not cause MAC-address table flushes unless the particular part of the network is completely isolated by the failure. This is due to the fact that the destination MAC addresses are not associated with a local port but with the remote RBridges that has the destination MAC connected. The RBridges will simply recalculate the routes to the new destination. This behavior is a direct result of topology-aware learning process that we’ll describe later. The net result is that topology changes do not have the devastating effect they have on STP-based networks.
- On a segment that has multiple RBridges connected, one is elected as “appointed forwarder” for every VLAN. Only the appointed forwarder is allowed to send/receive frames from a shared link, all others remain standby. This is required to ensure loop-free forwarding and avoid excessive flooding. This is very similar to the OTV behavior that we described above.
- In addition to data-plane MAC address learning, RBridges may explicitly propagate MAC addresses found on a locally connected VLAN to all other RBridges. This is an optional feature, but it allows for faster convergence and less flooding in the topology. The protocol is known as ESADI - End Station Address Distribution Information and looks very similar to control-plane learning found in OTV.
- The use of shortest-path routing allows for Equal-Cost Multipath Balancing and traffic engineer features found in routed IP network, thus resolving the problem of STP bottlenecks. Additionally, the use of appointed forwarders for every VLAN ensures better load balancing for multi-homed segments - again, a feature copied by OTV.
To summarize, TRILL keeps intact Ethernet’s dynamic data-plane learning feature that made the technology so “plug-and-play”. However, the amount of flooding is now controlled by use of distribution trees and hop counting. The net effect of flooding is significantly reduced due to the fact that topology changes do not flush the MAC address tables. Load balancing is much more effective and deterministic in TRILL networks. TRILL networks are easier to troubleshoot, as every RBridges associates the “flat” MAC address with the “location” in the network defined via the remote bridge nickname. Lastly, the problem of address table growth is somewhat resolved, due to the fact that MAC addresses need not to be known on every switch in the domain, but only on the switches that actually have connection to the end equipment.
Even though TRILL offers some benefits, the MAC address learning and frame flooding remains there. Furthermore, the problem of address space growth is not fully resolved, as with TRILL it results in “core-edge” address table asymmetry. If you are looking for a complete solution for all Ethernet issues, it is recommended to read the paper “Floodless in SEATTLE” (see Further Reading below), which offers significantly re-engineered Ethernet technology utilizing DHT (Distributed Hash Tables) found in peer-to-peer networks and link-state routing. SEATTLE offers truly floodless Ethernet and resolves the address space growth problem by making the global MAC address table work like a distributed database. Thanks to Daniel Ginsburg aka dbg for referring me to this wonderful reading!
Conclusions
Right now, OTV looks like an attempt to rapidly deploy VPLS functionality without relying on MPLS transport. This is probably driven by the growth need for deploying large data-centers and interconnecting them across convenient packet-switched networks at customer edge. OTV reduces flooding in network cores but makes convergence process slower in the presence of topology changes. Multicast traffic is forwarded in optimal manner using core network’s multicast services. If OTV is a first step toward TRILL, then it looks like a very promising technology. Otherwise it is just a VPLS replica with some optimizations. Still, I hope that one day OTV and VPLS branches will be merged and TRILL would become implemented in one common VPLS framework!
Further Reading
OTV Patent Paper
RBridges Draft Document
SEATTLE Technology
VPLS using LDP Signaling
VPLS using BGP Signaling
Multicasting in VPLS
Multihoming in VPLS
Multicast VPNs using Draft Rosen
Introduction to M-LSPs and Practical Examples
